This page is a resource for mentors, offering a structured curriculum to guide beginners through their data science journey. It provides mentors with a clear roadmap and curated materials to effectively support their mentees in building foundational skills and advancing in the field.
If you’re curious, consider using your browser to translate this page from Portuguese to English and explore the content!
Essa página sugere um roteiro de estudos em Ciência de Dados com foco em Aprendizado de Máquina. Ela abrange vários assuntos básicos e sugere continuações de estudo ou áreas de especialização que o mentorado pode escolher ao final.
Dependendo do nível técnico do mentorado no início da mentoria, várias etapas podem ser puladas. De forma geral, as atividades roteirizadas neste guia supõem um conhecimento equivalente ao ciclo básico de graduação em cursos da área de exatas, o qual detalharei com mais cuidado a seguir, dando ainda alternativas de cursos para quando esse pré-requisito não se aplica.
$\oint$ Os materiais apresentados aqui foram selecionados com grande intersecção com os recursos que utilizei durante minha preparação para ingressar no mercado de ciência de dados. Posteriormente, muitos desses materiais foram empregados em mentorias que conduzi com profissionais em início de carreira.
Pré-requisitos esperados do mentorado
Em uma conversa com o mentorado, é importante perceber se ele possui os pré-requisitos para seguir a sugestão de tópicos ou não. Caso contrário, diversas adaptações precisam ser feitas, principalmente no início, e já forneço algumas sugestões nesta seção.
Lógica de programação: Não é esperado que o mentorado já tenha experiência com Python, mas é desejável que tenha familiaridade com outra linguagem de programação e esteja confortável com laços de repetição, condições e operadores lógicos, além de estruturas de dados básicas como listas, dicionários e tipos básicos como strings. Caso o mentorado não possua esse conhecimento, o curso de introdução à programação do Kaggle pode ser um bom ponto de partida. Se for necessário dedicar ainda mais tempo a esses tópicos, aulas selecionadas da playlist de Python do Curso em Vídeo podem ser uma referência útil.
Estatística descritiva: É esperado que o mentorado tenha familiaridade com visualizações clássicas, como gráficos de dispersão, gráficos de barras/colunas, histogramas, box plots, gráficos de pizza, além de medidas-resumo de posição e dispersão, como média, mediana, percentis, desvio padrão, entre outros. Dependendo do nível do mentorado, uma simples revisão superficial do assunto (como nesta aula de análise descritiva da Univesp) pode ser suficiente. Em outros casos, pode ser necessário maior atenção, com o foco inicial das semanas dedicado ao ensino de Python por meio de exemplos de visualização de dados (por exemplo, utilizando o Kaggle Learn de Data Visualization com seaborn), em vez de começar diretamente com Aprendizado de Máquina.
Probabilidade: A linguagem do Aprendizado de Máquina é intrinsecamente probabilística. Recomenda-se que o mentorado esteja confortável com conceitos básicos de probabilidade (pelo menos em um nível introdutório). Isso inclui compreender a definição (ingênua) de espaço de probabilidade, probabilidade condicional e independência, variáveis aleatórias discretas e contínuas, as principais distribuições de variáveis aleatórias, bem como saber calcular esperanças, variâncias, correlações, entre outros. Não é necessário dominar todos os detalhes, mas, caso o tema seja intimidador, é recomendada uma revisão desses tópicos, como no curso Introdução à Probabilidade e Estatística (IPE) do professor Rafael Grisi da UFABC.
Matemática de forma geral: Além de estatística descritiva e probabilidade básica, outros tópicos matemáticos, como noções de otimização, cálculo diferencial, operações matriciais e estatística inferencial, são fundamentais para um entendimento mais aprofundado dos algoritmos de Aprendizado de Máquina. Se o mentorado possui uma base matemática frágil em algum desses tópicos (ou em todos), a especialização Mathematics for Machine Learning and Data Science Specialization pode ser uma excelente aliada, permitindo o estudo de aulas específicas ou uma imersão de algumas semanas nos fundamentos essenciais da Ciência de Dados.
Ensinamentos do HDFS: redundância é importante
Durante este guia de materiais de mentoria, ao selecionar partes específicas de cursos diferentes, vários assuntos podem ser abordados repetidamente, mas com uma abordagem ligeiramente diferente. Isso é intencional. Acredito que, para fortalecer essa base da forma mais robusta possível, é importante que os assuntos sejam realmente absorvidos, e revê-los algumas vezes ajuda a reforçar esse aprendizado. :)
0) Como usar esse guia de atividades de tutoria?
Logo abaixo do título da atividade, há uma breve motivação. Ela serve para que o tutor entenda por que aquela atividade faz sentido naquele momento (e pode ser compartilhada com o mentorado, caso o tutor julgue importante explicar a tarefa).
0.1) Requisitos sugeridos
Os pré-requisitos servem para indicar as dependências sugeridas entre as atividades, caso se deseje seguir uma ordem diferente ou pular etapas.
0.2) Descrição
A descrição é o texto sugerido para ser passado ao aluno na ferramenta utilizada para registrar as atividades. Recomendo o uso do Trello, uma ferramenta com estrutura no estilo Kanban, onde é possível organizar os cards em colunas (como “To Do”, “In Progress” e “Done”). Essa estrutura é bastante semelhante à forma como ferramentas de organização de tarefas são utilizadas em muitas equipes de dados que empregam o Agile (ou alguma variação dele).
É aqui que o link para o material de estudo deve ser disponibilizado. De forma geral, as recomendações oferecem o conteúdo de forma gratuita, e os materiais estão majoritariamente em inglês, com alguns tópicos em português. Caso algum link esteja quebrado, por favor, entre em contato comigo para que eu possa verificar e corrigir. :)
Cronograma
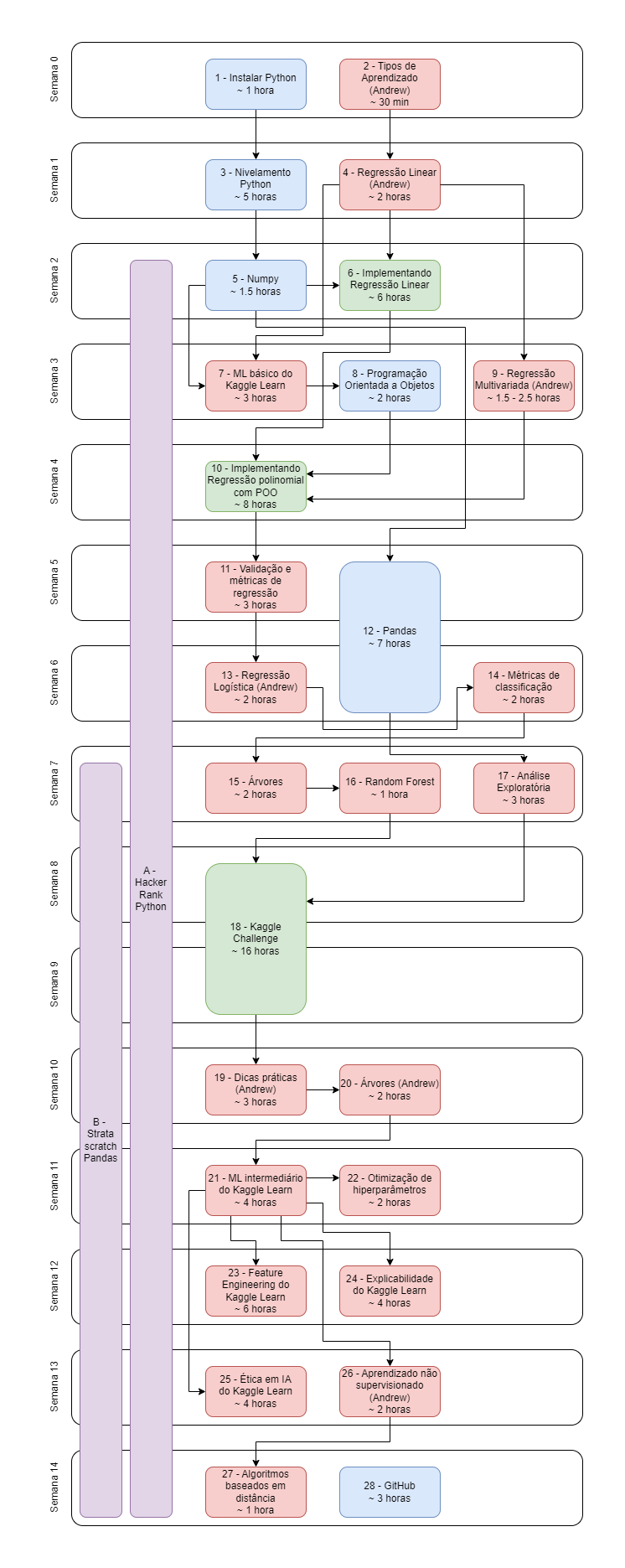
Concluída essa etapa de atividades, a sugestão é realizar algum desafio no Kaggle, levando em consideração o tempo restante da tutoria (considerando uma duração aproximada de 6 meses). Nesse momento, é importante compreender o problema de forma detalhada, e pode ser útil trabalhar em “releases”, em que, a cada x semanas, uma versão mais estruturada do modelo seja desenvolvida, incluindo novos testes.
Obviamente, essas atividades não estão gravadas em pedra e podem ser ajustadas conforme o interesse do tutorado. Por exemplo, um tutorado mais próximo da área de saúde pode ter interesse em redes neurais para imagens, por exemplo, o que tornaria relevante a substituição de algumas atividades, especialmente nas semanas finais.
Atividades recorrentes
As atividades recorrentes não são realizadas pontualmente nem finalizadas em sequência. São atividades que, uma vez atendidos os requisitos para sua execução, devem ser realizadas de forma contínua ao longo das semanas da tutoria.
A) HackerRank
O HackerRank oferece diversas playlists interessantes que ensinam, por meio de exercícios, particularidades do Python. Você terá a oportunidade de conhecer estruturas de dados não triviais enquanto revisita as que já domina, aprendendo novas maneiras de trabalhar com elas. Ferramentas como essa são frequentemente utilizadas em processos seletivos, principalmente para posições mais ligadas à Engenharia de Software, como a de Machine Learning Engineer.
A.1) Requisitos Sugeridos
Atividade 2.
A.2) Descrição
Dedicar pelo menos 1 hora por semana às atividades propostas nas playlists de Python do HackerRank. Com pouco tempo de prática, você terá explorado a maioria dos tipos de estruturas relevantes, o que ajudará a tornar seu código mais pythonic.

B) Stratascratch
Pandas é a principal biblioteca de manipulação de dados do Python. Aliada ao SQL, será a principal ferramenta para tratar dados no dia a dia da ciência de dados. Você só dominará a sintaxe do Pandas se utilizá-lo de forma recorrente. A ideia aqui é apresentar alguns exercícios, mais ou menos clássicos, para se familiarizar com as manipulações principais.
B.1) Requisitos sugeridos
Atividade 12.
B.2) Descrição
Realizar pelo menos 30 minutos de atividades propostas utilizando o Pandas do Stratascratch toda semana. Você também pode resolvê-las em SQL, o que pode ser útil para treinar essa ferramenta eventualmente.
Atividades Sequenciais
Sequência idealizada de atividades para o ciclo de estudos da mentoria.
1) Instalar Python (pelo Anaconda)
A ideia é preparar o ambiente para utilizar Jupyter Notebooks. Essas são ferramentas excelentes para exploração e, na prática, representam o ambiente mais adotado no dia a dia do cientista de dados para prototipação de código. Durante os encontros, é sempre útil apresentar os atalhos mais comuns e boas práticas, como deixar o notebook preparado para um “restart and run all” com resultados reproduzíveis (utilizando random states fixados). No entanto, abordar tudo isso agora pode acabar confundindo o mentorando. Eventualmente, ao final, podemos introduzir outras ferramentas, como IDEs, incluindo o VSCode, mas acredito que isso não seja útil no início.
1.1) Requisitos sugeridos
Não há.
1.2) Descrição
- Instalando Python para Aprendizado de Máquina - LAMFO. Não é necessário instalar o TensorFlow nem o Git por enquanto.
2) Aula introdutória da especialização (básica) de ML do Andrew
Aqui, o didático Andrew apresenta os tipos de aprendizado e oferece exemplos interessantes. É uma ótima oportunidade para pedir ao mentorando que sugira exemplos de problemas onde esses conceitos podem ser aplicados, além de motivar discussões sobre aplicações menos triviais.
2.1) Requisitos sugeridos
Não há.
2.2) Descrição
- Supervised Machine Learning: Regression and Classification by Andrew Ng
- #3 - What is machine learning? (5min)
- #4 - Supervised learning part 1 (6min)
- #5 - Supervised learning part 2 (7min)
- #6 - Unsupervised learning part 1 (8min)
- #7 - Unsupervised learning part 2 (3min)
3) Nivelamento Python (Kaggle Learn)
Python é A LINGUAGEM para Ciência de Dados: ela conta com muitas bibliotecas de alta qualidade já disponíveis e é amplamente adotada como padrão na esteira de produtização pelas empresas. O curso do Kaggle Learn é excelente porque foca nas partes mais úteis, especialmente considerando as principais bibliotecas de Aprendizado de Máquina. É um curso direcionado para quem está migrando de outra linguagem, ou seja, já parte do pressuposto de que o aluno tem conhecimento básico de lógica de programação.
3.1) Requisitos sugeridos
Atividade 1. Já assume conhecimento de programação básico em alguma linguagem.
3.2) Descrição
4) Aula de Regressão Linear da especialização (básica) de ML do Andrew
A Regressão Linear é um dos algoritmos mais simples de Aprendizado de Máquina, sendo o terreno ideal para introduzir as principais ideias do aprendizado supervisionado, além de apresentar nomenclaturas e desenvolver a intuição. É essencial que essa atividade seja realizada com muita atenção e cuidado.
O curso do Andrew Ng inclui alguns notebooks auxiliares que podem ser interessantes de explorar, dependendo do perfil do mentorado. No entanto, eu, pessoalmente, não os considero indispensáveis, pois as aulas são bastante visuais e já explicam bem os conceitos apresentados. Se for necessário, você pode baixar os notebooks em um repositório como este: Machine-Learning-Specialization-Coursera. Caso esse repositório fique indisponível, será relativamente fácil encontrar outros semelhantes pesquisando no Google.
4.1) Requisitos sugeridos
Atividade 2.
4.2) Descrição
- Supervised Machine Learning: Regression and Classification by Andrew Ng
- #9 - Linear regression model part 1 (10min)
- #10 - Linear regression model part 2 (6min)
- #11 - Cost function formula (9min)
- #12 - Cost function intuition (15min)
- #13 - Visualizing the cost function (8min)
- #14 - Visualization examples (6min)
- #15 - Gradient descent (8min)
- #16 - Implementing gradient descent (9min)
- #17 - Gradient descent intuition (7min)
- #18 - Learning rate (9min)
- #19 - Gradient descent for linear regression (6min)
- #20 - Running gradient descent (5min)
5) Introdução ao NumPy
NumPy é a principal ferramenta para manipulação de vetores e matrizes no Python, servindo como base para praticamente todas as outras bibliotecas importantes de Aprendizado de Máquina. Inicialmente, é fundamental compreender o básico dessa biblioteca e, com o tempo, buscar uma compreensão mais aprofundada para dominá-la.
5.1) Requisitos sugeridos
Atividade 3.
5.2) Descrição
Numpy in 5 min: Learn NUMPY in 5 minutes - BEST Python Library! (20 min)
Se precisar ver mais, esse vídeo aqui também é interessante: Complete Python NumPy Tutorial (Creating Arrays, Indexing, Math, Statistics, Reshaping) (1 hora)
6) Implementing from ground up: Regressão Linear Simples
Essa atividade serve como uma oportunidade para praticar e consolidar tudo o que foi aprendido até agora.
6.1) Requisitos sugeridos
Atividades 4 e 5.
6.3) Descrição
- Utilizando Python (principalmente o NumPy), você deve construir uma função que receba seu conjunto de dados
X_trainey_train(NumPy arrays) e retorne os pesos de uma regressão linear simples (ou seja,X_trainé unidimensional), utilizando o gradiente descendente para realizar o cálculo, conforme abordado no curso do Andrew Ng. Você pode criar os conjuntosX_trainey_traincomo preferir, mas o código deve ser robusto o suficiente para permitir a troca dos valores sem comprometer o funcionamento. - Defina critérios de parada que considerar apropriados para o gradiente descendente.
- Em seguida, com os pesos calculados, construa uma função que preveja os valores de
ypara um conjuntoXqualquer. - Pode ser interessante utilizar bibliotecas gráficas para visualizar o que está sendo feito. A mais famosa é o matplotlib. Nesta playlist do Corey Schafer há demonstrações de vários tipos de gráficos úteis.
7) Curso de básico de ML do Kaggle Learn
Exceto por problemas específicos, o dia a dia do cientista de dados não envolve criar modelos do zero. O scikit-learn é uma das bibliotecas mais robustas e amplamente utilizadas, com dezenas de modelos pré-construídos que seguem os melhores padrões de desenvolvimento de software. Além disso, conta com uma comunidade Open Source incrível que fornece suporte e orienta a evolução da biblioteca.
Este curso do Kaggle serve como uma introdução ao scikit-learn, sendo uma excelente oportunidade para aprender o padrão fit/predict, amplamente estabelecido e utilizado no campo de Aprendizado de Máquina.
7.1) Requisitos sugeridos
Atividades 4 e 5.
7.2) Descrição
Extra: pode ser útil dar uma lida rápida na página de “getting started” do scikit-learn.
8) Introdução à Programação Orientada a Objetos (POO)
A orientação a objetos é o paradigma de programação principal do Python. A forma de abstração que ele nos oferece é muito poderosa, permitindo a construção de códigos complexos de maneira estruturada e reaproveitável, além de facilitar a manutenção. O objetivo desta atividade não é se tornar um mestre em POO, mas ter uma visão geral para saber que ela existe e compreender como o scikit-learn e outras bibliotecas do Python a utilizam. No futuro (provavelmente fora do escopo desta mentoria básica inicial), esse tópico pode ser revisitado, aprofundando-se no uso de heranças e boas práticas, como os princípios SOLID e os design patterns.
8.1) Requisitos sugeridos
Atividade 7.
8.2) Descrição
- Python OOP Tutorial 1: Classes and Instances (15 min)
Tente criar um cenário simples em Python no qual você utiliza classes. Por exemplo, crie uma classe abstrata que represente a entidade “Cachorro” e que tenha dois atributos: “nome” e “raça”. O cachorro também deve ter um método chamado “pedido_para_sentar”, que recebe uma string. Se essa string for igual ao nome do cachorro, o método deve imprimir que o cachorro sentou.
- Extra: uma discussão sobre diferentes formas de se programar (paradigmas): 1.1 - Programação Funcional em Haskell: Paradigmas de Programação (27 min) - O Python tem várias coisas bem úteis de programação funcional então é legal conhecer por cima as ideias também.
9) Aula de Regressão Linear Multivariada (e polinomial) da especialização (básica) de ML do Andrew
Na vida real, utilizamos dezenas, centenas ou até milhares de variáveis para realizar nossas previsões, e não apenas uma, como na regressão linear simples. Embora ainda seja um algoritmo relativamente simples, generalizar o caso da regressão linear simples já nos dá uma ideia de onde queremos chegar eventualmente. Além disso, nesta aula, o Andrew explica o conceito de vetorização de código (evite usar loops for!).
9.1) Requisitos sugeridos
Atividade 4.
9.2) Descrição
- Supervised Machine Learning: Regression and Classification by Andrew Ng
- #21 - Multiple features (9min)
- #22 - Vectorization part 1 (6min)
- #23 - Vectorization part 2 (6min)
- #24 - Gradient descent for multiple linear regression (7min)
- #25 - Feature scaling part 1 (6min)
- #26 - Feature scaling part 2 (7min)
- #27 - Checking gradient descent for convergence (5min)
- #28 - Choosing the learning rate (6min)
- #29 - Feature engineering (3min)
- #30 - Polynomial regression (5min)
Em particular, nessa atividade, pode ser necessário revisar operações matriciais. Um material rápido e direto ao ponto para isso pode ser algumas das aulas da versão anterior desse curso:
- Machine Learning — Andrew Ng, Stanford University [FULL COURSE]
- Lecture 3.1 — Linear Algebra Review : Matrices And Vectors - 8:46
- Lecture 3.2 — Linear Algebra Review : Addition And Scalar Multiplication - 6:54
- Lecture 3.3 — Linear Algebra Review : Matrix Vector Multiplication - 13:40
- Lecture 3.4 — Linear Algebra Review : Matrix-Matrix Multiplication - 11:10
- Lecture 3.5 — Linear Algebra Review : Matrix Multiplication Properties - 9:03
- Lecture 3.6 — Linear Algebra Review : Inverse And Transpose - 11:14
Se quiser saber mais sobre o que Andrew chama de “normal equation”, que nada mais é do que a solução analítica dos pesos na regressão linear (em contraste com o método numérico iterativo aproximado fornecido pelo gradiente descendente):
- Machine Learning — Andrew Ng, Stanford University [FULL COURSE]
- Lecture 4.6 — Linear Regression With Multiple Variables : Normal Equation - 16:18
- Lecture 4.7 — Linear Regression With Multiple Variables : Normal Equation Non Invertibility - 5:59
10) Implementing from ground up: Regressão Polinomial + POO
A estrutura orientada a objetos do scikit-learn precisa se tornar sua aliada. O objetivo desta atividade é explorar um pouco a “caixa preta” dos estimadores do scikit-learn, implementando do zero o caso particular de regressão multivariada (quando as dimensões extras correspondem a potências da primeira componente, como Andrew explica em um dos vídeos da atividade 9).
A ideia aqui é se familiarizar um pouco mais com a forma como o scikit-learn funciona, praticando POO.
10.1) Requisitos sugeridos
Atividades 4, 8 e 9.
10.2) Descrição
O objetivo desta atividade é estruturar, de forma mais elegante, o que você desenvolveu na atividade 8, encapsulando o código em uma classe no formato dos estimadores apresentados no curso do Kaggle sobre scikit-learn. Idealmente, boa parte do código anterior será reaproveitada nesta atividade.
- Você deve criar uma classe chamada
PolynomialRegression, que recebe um parâmetro em sua inicialização chamadodegree. - Essa classe precisa conter dois métodos:
fitepredict. O métodofitdeve receber duas entradas:Xey. OXdeve atender à formaX.shape = (n_samples, 1)e oydeve atender à formay.shape = (n_samples,), onden_samplesé o número de amostras. Por exemplo,X = np.array([[1, 2, 3]]).Tey = np.array([1, 2, 3])satisfazem essas condições (apenas como exemplo; use outros valores quaisquer). O métodopredictdeve receber apenas uma entrada,X, com as mesmas restrições de.shapedescritas anteriormente. - O método
fitdeve calcular os polinômios deXaté o grau definido emdegree(sugestão: utilize um list comprehension junto comnp.hstack) e, em seguida, aplicar o gradiente descendente para encontrar os coeficientes dessa regressão linear multivariada. Isso deve ser uma generalização da função que você desenvolveu anteriormente para a regressão linear simples. - Os coeficientes aprendidos durante o
fitdevem ser armazenados em atributos da classe com um sufixo de underline no nome. Essa é a convenção adotada pelo scikit-learn para guardar informações aprendidas durante o treinamento. Finalmente, o método
predict, que recebe oX, deve aplicar a mesma transformação polinomial nesse novoXe realizar as multiplicações da regressão múltipla (algo comoX_poly * w + b) para obter as previsões, que devem ser retornadas pela função.- Extra: Pode ser interessante consultar como o scikit-learn sugere a implementação de modelos. Não se preocupe com o que eles chamam de
BaseEstimatore mixins, que é um assunto mais avançado de orientação à objetos.
11) Validação de modelos de regressão
Em relação à atividade prática, é de nosso interesse determinar, por exemplo, qual o melhor valor de degree a ser utilizado em um modelo. Para avaliar o desempenho do modelo e definir o que significa ser “melhor” ou “pior”, assim como no caso da regressão linear, precisamos estabelecer uma métrica de avaliação. Nesta atividade, exploraremos algumas métricas além da “mean squared error” e aplicaremos essa ideia na atividade anterior.
11.1) Requisitos sugeridos
Atividade 10.
11.2) Descrição
Métricas de Regressão
- Regression Metrics Review I - How to Win a Data Science Competition Learn from Top Kagglers (15min)
- Regression Metrics Review II - How to Win a Data Science Competition Learn from Top Kagglers (9min)
Obs: Os vídeos desta seção estão hospedados em uma plataforma de compartilhamento de vídeos asiática, pois os originais, que estavam no Coursera, tornaram-se indisponíveis devido às sanções aplicadas à Rússia pela guerra na Ucrânia. No Coursera, os cursos originados de universidades russas foram desativados.
No curso introdutório de Aprendizado de Máquina do Kaggle Learn, que você realizou, foram apresentadas ideias iniciais sobre validação de modelo utilizando um conjunto de validação (hold-out). Um exercício interessante é aplicar essa mesma ideia à atividade anterior (10), separando o conjunto de dados em uma parte para treino e outra para teste.
- Training and testing - Machine Learning for Trading (3 min)
- Escolha algumas das métricas discutidas disponíveis no scikit-learn e analise como elas se comportam (tanto no conjunto de treino quanto no de teste) ao variar o valor de
degreena sua implementação. - Fundamentos de Aprendizagem de Máquina: Viés e Variância - StatQuest (7 min)
Mais adiante, discutiremos com mais profundidade os conceitos de viés/variância e underfitting/overfitting. Por ora, tente refletir sobre o que acontece com o modelo polinomial ao alterar o valor de degree. Para quais valores de degree ocorre underfitting? E para quais valores ocorre overfitting?
12) Introdução ao Pandas
O Pandas é a biblioteca de manipulação de dados mais amplamente utilizada para estruturar seus dados em Python. Aliada ao Spark e ao SQL, ela compõe um stack extremamente robusto para diferentes tarefas e cenários de manipulação de dados. O Pandas é, talvez, a mais natural para aprender quando se está estudando Python, e dominá-la facilitará o aprendizado das outras ferramentas.
12.1) Requisitos sugeridos
Atividade 5.
12.2) Descrição
Algumas referências. Caso ache que estão muito redundantes, sinta-se à vontade para pular algumas delas.
- Kaggle Learn - Intro to Pandas (4h).
- Pandas for Data Science in 20 Minutes : Python Crash Course (23 min)
- Complete Python Pandas Data Science Tutorial! (Reading CSV/Excel files, Sorting, Filtering, Groupby) (~1 hora)
- Python pandas — An Opinionated Guide (~2 horas)
13) Aula de Regressão Logística da especialização (básica) de ML do Andrew
A regressão logística é uma generalização natural da regressão linear para o caso de classificação binária, em que, por construção, espera-se que o output do modelo seja um valor entre 0 e 1, com interpretação como a probabilidade de uma das classes. Nesta aula do Andrew, são abordados alguns tópicos adicionais, como underfitting, overfitting e regularização.
13.1) Requisitos sugeridos
Atividade 11.
13.2) Motivação
- Supervised Machine Learning: Regression and Classification by Andrew Ng
- #31 - Classification Motivations (9min)
- #32 - Logistic regression (9min)
- #33 - Decision boundary (10min)
- #34 - Cost function for logistic regression (11min)
- #35 - Simplified Cost Function for Logistic Regression (5min)
- #36 - Gradient Descent Implementation (6min)
- #37 - The problem of overfitting (11min)
- #38 - Addressing overfitting (8min)
- #39 - Cost function with regularization (9min)
- #40 - Regularized linear regression (8min)
- #41 - Regularized logistic regression (5min)
Vale dar uma olhada rápida na ideia de generalização para o caso multiclasse:
- Machine Learning — Andrew Ng, Stanford University [FULL COURSE]
- Lecture 6.7 — Logistic Regression : MultiClass Classification OneVsAll (6min)
14) Métricas de classificação
Assim como no caso da regressão, existem diversas maneiras de avaliar a qualidade de um modelo em problemas de classificação.
14.1) Requisitos sugeridos
Atividade 13.
14.2) Descrição
- The 5 Classification Evaluation metrics every Data Scientist must know
- Classification Metrics Review - How to Win a Data Science Competition Learn from Top Kagglers
Obs: Os vídeos desta seção estão hospedados em uma plataforma de compartilhamento de vídeos asiática, pois os originais, que estavam no Coursera, tornaram-se indisponíveis devido às sanções aplicadas à Rússia pela guerra na Ucrânia. No Coursera, os cursos originados de universidades russas foram desativados.
- Uma sugestão mais rigorosa é o capítulo sobre métricas de classificação do livro do DataLab
15) Árvores de Decisão e Regressão
Algoritmos baseados em árvores estão entre os mais utilizados, de maneira geral, para trabalhar com dados tabulares. Compreender bem o caso básico é essencial para entender as formas mais robustas de utilizá-los, especialmente quando empregamos comitês.
15.1) Requisitos sugeridos
Atividade 14.
15.2) Descrição
- CART - Classification And Regression Trees - StatQuest
- Decision and Classification Trees, Clearly Explained!!! (18min)
- Decision Trees, Part 2 - Feature Selection and Missing Data (5min)
- Regression Trees, Clearly Explained!!! (22min)
How to Prune Regression Trees, Clearly Explained!!! (16min)
- Decision Trees na Prática (Scikit-learn / Python) - Mario Filho (30min)
16) Random Forest
As Random Forests são um poderoso exemplo de comitês baseados em árvores de decisão, projetados para aumentar a precisão e a robustez dos modelos. Compreender suas ideias centrais, como bootstrapping, o erro fora da amostra (OOB) e a importância das variáveis, é essencial para explorar seu potencial em dados tabulares.
16.1) Requisitos sugeridos
Atividade 15.
16.2) Descrição
- Bootstrapping Main Ideas!!! - StatQuest (9min)
- StatQuest: Random Forests Parte 1 - Construindo, Usando e Avaliando - StatQuest (10min)
- Random Forest na Prática (Scikit-learn / Python) - Mario Filho (25min)
- Out-of-Bag Error (OOB Error) - No Learning
- Random Forest - Feature Importance - I2ML (8min)
- Permutation feature importance (Obs: Não só aplicável às Random Forests)
- Random Forest - Machine Learning Interview Q&A for Data Scientists - Data Science Interviews - Emma Ding
17) Análise Exploratória de Dados
Na prática, antes da modelagem, é muito importante entender quais variáveis o cientista tem disponíveis para a criação do modelo. Nem sempre o problema está bem definido, e a delimitação do que se deseja modelar (e quais métricas otimizar) pode surgir de um bom entendimento dos dados disponíveis, em conjunto com alinhamentos com a área de negócios interessada.
- Pensar em hipóteses de negócio que você gostaria de validar é uma ótima maneira de realizar uma análise exploratória. Será que você já tem alguma intuição sobre o problema que possa, inclusive, ajudá-lo a modelar o problema de uma forma diferente no futuro?
- Em um problema de inadimplência de crédito (previsão de se uma pessoa irá pagar ou não uma dívida), por exemplo, pode-se ter a intuição de que, para pessoas de baixa renda, a existência de uma dívida não quitada anterior pode ser crucial para prever se elas pagarão o próximo empréstimo. Enquanto isso, para pessoas de alta renda, esse fator pode ser menos relevante. Esse tipo de pergunta pode ser testado diretamente, e essa hipótese pode se tornar uma regra de negócio que funcione como um benchmark que você desejará superar com o modelo. Será que essa regra, sozinha, já apresenta uma performance boa o suficiente que sequer justifique a criação de um modelo?
- Além disso, a hipótese pode ajudá-lo a compreender onde está o maior foco de interesse na modelagem. Por exemplo, se você tem o valor da dívida, pode agrupar os dados para identificar quais grupos, caso sejam mal identificados pelo modelo, podem gerar maiores prejuízos. Imagine que, embora pessoas de alta renda sejam minoria na base de desenvolvimento (10%, por exemplo), elas estejam associadas a 90% do valor total em empréstimos. Identificar corretamente os maus pagadores nesse grupo pode ser muito mais importante do que identificá-los de forma geral na população. Isso pode orientar as etapas de modelagem e avaliação, levando a segmentar métricas, usar
sample_weightspara valorizar grupos de interesse e até mesmo dividir o modelo por faixa de renda.
- Estudar sua amostra de desenvolvimento, utilizando gráficos e estatísticas, pode fornecer insights sobre quais variáveis estão relacionadas ao problema e possíveis técnicas de feature engineering que podem ser aplicadas, além de identificar problemas que precisam ser resolvidos para uma modelagem adequada.
- É comum tentar filtrar algumas variáveis nesta etapa com base em medidas de correlação. Embora isso possa ser mais eficaz em etapas posteriores do pipeline de desenvolvimento, pode ser necessário fazê-lo durante a exploração se o problema tiver muitas colunas e o tempo for curto, exigindo o foco nas mais relevantes. Rodar análises de correlação simples ou utilizar algoritmos que medem a importância das variáveis (como algoritmos baseados em árvores) pode ser muito útil, mas deve ser feito com cautela.
- Conhecer as variáveis disponíveis, aliado a um entendimento do negócio, pode inspirá-lo a criar variáveis que simplifiquem o trabalho do modelo (especialmente árvores, que só conseguem fazer cortes paralelos aos eixos). Por exemplo, uma variável muito relevante em crédito é o “comprometimento de renda”, ou seja, a porcentagem do salário que precisaria ser reservada para pagar a parcela de um financiamento ativo (
valor_parcela/valor_salario). Criá-la nesta etapa e avaliá-la por meio de gráficos pode ser uma atividade exploratória muito útil. - Bases de dados frequentemente apresentam problemas como valores vazios ou, pior, valores preenchidos de forma incorreta. Se uma variável só deveria conter valores dentro de um certo intervalo e você encontra valores fora desse intervalo, é necessário investigar o motivo. Analisar criticamente os valores pode ajudar a traçar estratégias para tratá-los ou até mesmo descartá-los (com cuidado, pois excluir linhas no conjunto de teste só deve ser feito se aquilo realmente não ocorrer na vida real). (Em um problema de Kaggle ou portfólio, essa resposta raramente estará disponível, mas em uma empresa, esse pode ser o momento de conversar com a engenharia e entender como os dados serão fornecidos para o modelo. Também pode ser o caso de alinhar com a área de negócios para adaptar a esteira de decisão quando faltarem informações, por exemplo.)
- Além disso, esse entendimento orienta a escolha de modelos mais apropriados para o tipo de dados disponíveis.
- Por exemplo, escolher modelos que lidem nativamente bem com variáveis categóricas (como o CatBoost).
- Para valores faltantes, dependendo do caso (MCAR, MAR ou MNAR), estratégias de imputação podem ser definidas nesta etapa (e testadas posteriormente na otimização de hiperparâmetros) ou pode-se optar por modelos que lidem nativamente com dados faltantes (como o LightGBM).
- Por fim, explorar tendências temporais nos dados é essencial. Aprendizado de máquina pressupõe que os dados sejam estáveis ao longo do tempo, o que nem sempre é a realidade. Em muitas aplicações, é importante segmentar os dados respeitando a lógica temporal, e a análise exploratória pode indicar se isso é relevante para o problema em questão.
Opinião pessoal (também conhecido como desabafo):
Pensando principalmente em aprendizado supervisionado, os pontos acima (validação de hipóteses de negócio, estudo de variáveis relevantes, criação de variáveis novas, identificação de problemas, entre outros) são os principais objetivos de uma análise exploratória de dados e devem ser o foco da exploração. Criar gráficos “por criar”, que não trazem informações relevantes, deve ser evitado, pois tornam a análise prolixa e desviam do objetivo principal: o modelo final.
É fácil se desviar desses objetivos, mas vale sempre se perguntar: “Por que estou criando este gráfico ou calculando esta estatística?” Se o motivo estiver claro, então provavelmente faz sentido fazê-lo.
Pode parecer uma visão dura sobre as análises exploratórias, mas é muito comum observar, especialmente em cientistas de dados iniciantes (em cases de entrevistas e projetos de portfólio), notebooks extensos com inúmeros gráficos e comandos
.head()que dificultam a navegação do código sem agregar valor ao processo de modelagem ou à narrativa do problema. Em 99% dos casos, esses elementos parecem desconectados do problema de interesse e, se excluídos do notebook, não alterariam o resultado final.Em casos em que não há necessariamente um modelo envolvido, aprofundar-se na análise exploratória pode fazer sentido, mas ainda assim raramente fugiria das motivações anteriores.
17.1) Requisitos sugeridos
Atividades 12.
17.2) Descrição
- Exemplo de notebook que realiza uma análise exploratória focada em procurar erros nos dados.
- Exemplo de notebook que gera gráficos interessantes das variáveis analisando quais fazem sentido para o modelo.
- Exemplo de notebook que cria hipóteses de negócio como modelos e depois compara performance dessas hipóteses contra modelos de ML.
Extras:
- Iremos discutir aspectos de validação out-of-time no futuro, mas este notebook apresenta uma análise exploratória para estudo de estabilidade temporal com uma técnica interessante:
18) Kaggle Challenge
Neste ponto, o mentorado já adquiriu o conhecimento necessário para realizar um ciclo completo de machine learning: desde a escolha de um dataset até a aplicação de um modelo, passando pela limpeza dos dados e avaliação dos resultados. Este desafio no Kaggle oferece uma oportunidade prática para consolidar e aplicar os aprendizados em um cenário prático.
18.1) Requisitos sugeridos
Atividades 16 e 17.
18.2) Descrição
Escolher um dataset do Kaggle e limpar os dados + aplicar um modelo de ML, avaliando os resultados (qual métrica utilizar pensando no problema que estou preocupado em resolver?)
- Find Open Datasets and Machine Learning Projects - Kaggle
- Sugestão: Heart Attack Analysis & Prediction Dataset
19) Aula sobre dicas práticas da especialização (básica) de ML do Andrew
Esta atividade oferece uma visão prática e estratégica do ciclo de vida completo de um modelo de machine learning supervisionado, com foco em validação, análise de erros e iteração. Além disso, aborda tópicos fundamentais como MLOps e ética, ajudando o mentorado a conectar teoria e prática de forma holística.
19.1) Requisitos sugeridos
Atividade 18.
19.2) Descrição
Infelizmente, a partir do segundo curso do Andrew, é necessário se inscrever pelo Coursera porque os vídeos não estão disponíveis no YouTube. Não se preocupe, o conteúdo continua gratuito se você se inscrever como ouvinte.
- Advanced Learning Algorithms by Andrew Ng
- Semana 3: Advice for applying machine learning
- Deciding what to try next (3min)
- Evaluating a model (10min)
- Model selection and training/cross validation/test sets (13min) - Obs1*
- Diagnosing bias and variance (11min)
- Regularization and bias/variance (10min)
- Establishing a baseline level of performance (9min) - Obs2*
- Learning curves (11min)
- Deciding what to try next revisited (8min)
- Bias/variance and neural networks (10min) - Pode pular ou assistir apenas “por cima” por ser específico de Redes Neurais
- Iterative loop of ML development (7min)
- Error analysis (8min)
- Adding data (14min)
- Transfer learning: using data from a different task (11min) - Pode pular ou assistir apenas “por cima” por ser específico de Redes Neurais
- Full cycle of a machine learning project (8min)
- Fairness, bias, and ethics (9min)
- Error metrics for skewed datasets (11min)
- Trading off precision and recall (11min)
- Obs1*: O Andrew usa o termo “cross validation” de uma forma diferente do tradicional, que costuma ser usada quando estamos falando do k-fold ou alguma variação dele (como o
sklearn.model_selection.StratifiedKFoldou osklearn.model_selection.TimeSeriesSplit). O conjunto que ele se refere é comumente chamado de conjunto de validação (enquanto o último conjunto é chamado de conjunto de teste). - Obs2*: O seu baseline normalmente é um algoritmo mais simples (ou o modelo que já existe) numa aplicação real.
20) Aula de árvores de decisão da especialização (básica) de ML do Andrew
As árvores de decisão são modelos fundamentais para resolver problemas tanto de classificação quanto de regressão, servindo de base para técnicas mais avançadas como Random Forests e XGBoost. Esta aula do Andrew Ng aprofunda os conceitos de aprendizado, medição de pureza e seleção de divisões, consolidando uma compreensão sólida do funcionamento e aplicações desse tipo de modelo.
20.1) Requisitos sugeridos
Atividade 19.
20.2) Descrição
Infelizmente, a partir do segundo curso do Andrew, é necessário se inscrever pelo Coursera porque os vídeos não estão disponíveis no YouTube. Não se preocupe, o conteúdo continua gratuíto se você se inscrever como ouvinte.
- Advanced Learning Algorithms by Andrew Ng
- Semana 4: Decision trees
- Decision tree model (7min)
- Learning Process (11min)
- Measuring purity (7min)
- Choosing a split: Information Gain (11min)
- Putting it together (9min)
- Using one-hot encoding of categorical features (5min)
- Continuous valued features (6min)
- Regression Trees (optional) (9min)
- Using multiple decision trees (3min)
- Sampling with replacement (3min)
- Random forest algorithm (6min)
- XGBoost (6min)
- When to use decision trees (6min)
21) Curso de intermediário de ML do Kaggle Learn
O curso intermediário de Machine Learning do Kaggle é uma oportunidade de aprofundar conceitos essenciais, como imputação de valores ausentes, validação e ajuste de modelos. Além disso, a inclusão de referências sobre validação out-of-time e out-of-space ajuda a explorar técnicas avançadas para avaliar modelos em cenários mais desafiadores e próximos da realidade.
21.1) Requisitos sugeridos
Atividade 20.
21.2) Descrição
- Kaggle Learn - Intermediate Machine Learning (4h).
- Validação out of time - Experian (Serasa).
- Diagrama de validação out-of-space e out-of-time - Documentação do fklearn - Nubank.
22) Otimização de hiperparâmetros
A otimização de hiperparâmetros é uma etapa crucial para maximizar o desempenho dos modelos de machine learning. Esta atividade apresenta as principais abordagens, como Grid Search e alternativas mais eficientes, ajudando o mentorado a compreender quando e como ajustar hiperparâmetros de maneira estratégica para diferentes tipos de problemas.
22.1) Requisitos sugeridos
Atividade 21.
22.2) Descrição
- Hyperparameter optimization - Wikipedia
- Hyperparameter Optimization - The Math of Intelligence #7 - Siraj Raval (10min). Ele é meio impreciso em alguns poucos momentos não muito relevantes e entra em alguns tópicos que não são essenciais, mas é interessante para ver a ideia geral.
- Nunca Mais Use Grid Search Para Ajustar Hiperparâmetros - Mario Filho (32min)
23) Curso de feature engineering do Kaggle Learn
O feature engineering é uma etapa essencial para aumentar a qualidade e o desempenho dos modelos de machine learning, permitindo extrair o máximo de informações úteis dos dados. Este curso do Kaggle Learn e as referências complementares ajudam o mentorado a dominar técnicas como encoding, manipulação de datas e criação de variáveis mais informativas, consolidando uma base sólida para modelagem avançada.
23.1) Requisitos sugeridos
Atividade 21.
23.2) Descrição
- Kaggle Learn - Feature Engineering (5h).
- Aula avulsa do curso de Data Cleaning sobre dataframes com colunas do tipo data (1h).
- One-Hot, Label, Target e K-Fold Target Encoding, claramente explicados!!! - StatQuest
24) Curso de explicabilidade do Kaggle Learn
Explicabilidade em machine learning é fundamental para entender como os modelos tomam decisões, aumentando a confiança e a transparência em suas previsões. Este curso do Kaggle Learn explora ferramentas como SHAP values, permitindo que o mentorado interprete modelos complexos e identifique os fatores mais relevantes na tomada de decisão, com aplicações práticas e acessíveis.
24.1) Requisitos sugeridos
Atividade 21.
24.2) Descrição
- Kaggle Learn - Machine Learning Explainability (4h).
- SHAP Values Explained Exactly How You Wished Someone Explained to You - Samuele Mazzanti
25) Curso de ética do Kaggle Learn
A ética em IA é essencial para desenvolver soluções responsáveis, justas e alinhadas com os valores sociais.
25.1) Requisitos sugeridos
Atividade 21.
25.2) Descrição
26) Aula aprendizado não supervisionado da especialização (básica) de ML do Andrew
O aprendizado não supervisionado é uma abordagem poderosa para descobrir padrões ocultos e identificar anomalias em dados sem rótulos. Esta aula do Andrew Ng apresenta fundamentos como clustering com K-means e detecção de anomalias, permitindo ao mentorado explorar aplicações práticas dessas técnicas.
26.1) Requisitos sugeridos
Atividade 21.
26.2) Descrição
Infelizmente, a partir do segundo curso do Andrew, é necessário se inscrever pelo Coursera porque os vídeos não estão disponíveis no YouTube. Não se preocupe, o conteúdo continua gratuíto se você se inscrever como ouvinte.
- Unsupervised Learning, Recommenders, Reinforcement Learning
- Semana 1: Unsupervised learning
- What is clustering? (4min)
- K-means intuition (6min)
- K-means algorithm (9min)
- Optimization objective (11min)
- Initializing K-means (8min)
- Choosing the number of clusters (7min)
- Finding unusual events (11min)
- Gaussian (normal) distribution (10min)
- Anomaly detection algorithm (11min)
- Developing and evaluating an anomaly detection system (11min)
- Anomaly detection vs. supervised learning (8min)
- Choosing what features to use (14min)
27) Algoritmos baseados em distância
Algoritmos baseados em distância, como KNN e K-Means, utilizam medidas de similaridade geométrica para classificação, regressão e clustering. Compreender esses métodos é essencial para explorar técnicas simples e eficazes em aprendizado de máquina.
27.1) Requisitos sugeridos
Atividade 26.
27.2) Descrição
- K-nearest neighbors, Clearly Explained - StatQuest (5min)
- K-means clustering = StatQuest (9min)
- Chapter 3 - GEOMETRY AND NEAREST NEIGHBORS - A Course in Machine Learning by Hal Daumé III
- Generalizando distância - Carlo Lemos
28) Introdução a Version Control System (Git/GitHub)
O Git é uma ferramenta essencial para controle de versão, permitindo que você acompanhe e gerencie alterações em seu código de forma eficiente e segura. Ele é amplamente utilizado em projetos de software para colaborar em equipes, revisar mudanças e integrar diferentes partes de um projeto sem conflitos.
O GitHub, por sua vez, é uma plataforma que aproveita o poder do Git, oferecendo recursos adicionais como hospedagem de repositórios, integração contínua, controle de acesso e colaboração em projetos. Dominar essas ferramentas não é apenas importante para gerenciar seus próprios projetos, mas também essencial para trabalhar em equipes modernas, onde o versionamento e a rastreabilidade são cruciais para a produtividade e qualidade do trabalho.
28.1) Requisitos sugeridos
Não há.
28.2) Descrição
- GitHub - Guia Completo do Iniciante - Felipe - Dev Samurai (22min)
- Introdução ao GitHub - Treinamento Microsoft
- Learn Git Branching
Discussões extras e alguns tópicos de estudo individual pós tutoria
Essa é uma lista (não exaustiva) de temas interessantes que podem ser usados para se aprofundar (para mentorados que já estão mais avançados) após o ciclo idealizado. Aqui a escolha deve ser do mentorado sobre os assuntos pensando também no tempo restante e na relevância dos assuntos.
SQL
Provavelmente o assunto mais importante que ficou faltando no currículo inicial da tutoria. Vale a pena ter um nível básico de SQL para aplicar para vagas.
Algoritmos Clássicos de ML que não foram vistos anteriormente, mas são importantes
- Supervisionado
- StatQuest: Linear Discriminant Analysis (LDA) clearly explained
- Naive Bayes, Clearly Explained!!!
- Gaussian Naive Bayes, Clearly Explained!!!
- Support Vector Machines, Clearly Explained!!!
- Support Vector Machines Part 2: The Polynomial Kernel (Part 2 of 3)
- Support Vector Machines Part 3: The Radial (RBF) Kernel (Part 3 of 3)
- Redução de Dimensionalidade
- Clustering
eXplainable AI
- You are underutilizing SHAP values: understanding populations and events - Estevão Uyrá
- xAI - Fabrício Olivetti - UFABC
- The Science Behind InterpretML: Explainable Boosting Machine
GenAI
- ChatGPT Prompt Engineering for Developers - deeplearning.ai
- Building Systems with the ChatGPT API - deeplearning.ai
- LangChain for LLM Application Development - deeplearning.ai
- Functions, Tools and Agents with LangChain - deeplearning.ai
- Building and Evaluating Advanced RAG Applications - deeplearning.ai
Cursos de Aprendizado de Máquina com um pouco mais de rigor
Boosting Trees
- Bagging vs Boosting - Ensemble Learning In Machine Learning Explained - WhyML
- AdaBoost, Clearly Explained
- Gradient Boost playlist - StatQuest
- XGBoost playlist - StatQuest
- Why XGBoost is better than GBM? - Damien Benveniste
- XGBoost vs LightGBM: How Are They Different - neptune.ai/blog
- Ensemble: Boosting, Bagging, and Stacking - Machine Learning Interview Q&A for Data Scientists - Emma Ding
- Gradient Boosting (GBM) and XGBoost - Machine Learning Interview Q&A for Data Scientists - Emma Ding
MLOps
- Curso Machine Learning Engineering for Production (MLOps) by Andrew Ng
- Monitoramento de Modelos
Fairness
- A Justiça da Sociedade Algorítmica - Ramon Vilarino
- Fairness em Machine Learning - Nubank ML Meetup - Tatyana Zabanova
- Dealing with bias and fairness in AI systems - Pedro Saleiro
Redes Neurais (Deep Learning)
- Kaggle Learn - Intro to Deep Learning
- Advanced Learning Algorithms by Andrew Ng
- Semana 1: Neural Networks
- Semana 2: Neural network training
- Deep Learning Specialization by Andrew Ng
- Transformers with Hugging Face
- Tranformers doc - Hugging Face
Shallow NLP
- Python Tutorial: re Module - How to Write and Match Regular Expressions (Regex) - Corey Schafer
- Modelo Bag of Words - IA Expert Academy
- TF-IDF (Term Frequency - Inverse Document Frequency) - IA Expert Academy
- Remoção de stop words com Python e NLTK - IA Expert Academy
- Stemming com NLTK e Python - IA Expert Academy
- Word2Vec - Skipgram and CBOW - The Semicolon
- Processamento Neural de Linguagem Natural em Português - Coursera USP
Sistemas de Recomendação (RecSys)
- Unsupervised Learning, Recommenders, Reinforcement Learning by Andrew Ng
- Semana 2: Recommender systems
Aprendizado por Reforço
- Multi-Armed Bandit - Matheus Facure
- Multi-Armed Bandit - Guilherme Marmerola
- Introdução ao Aprendizado por Reforço - Itau Data Science Meetup - Caique R. Almeida
- Unsupervised Learning, Recommenders, Reinforcement Learning by Andrew Ng
- Semana 3: Reinforcement learning
- Deep Reinforcement Learning Course - Hugging Face
Séries temporais com Aprendizado de Máquina
- Multiple Time Series Forecasting With Scikit-Learn - Mario Filho
- sktime - A Unified Toolbox for ML with Time Series - Markus Löning - PyData Global 2021
Robustez de Modelo
- Como leakage de dados acaba com backtesting - Nubank ML Meetup - Tatyana Zabanova
- Generalização de domínio, invariância e a Floresta Temporalmente Robusta - Nubank ML Meetup - Luis Moneda
- Train/test mismatch e adaptação de domínio - A Course in Machine Learning by Hal Daumé III
Inferência Causal
- Causal Inference for The Brave and True - Matheus Facure
- Notas de aula de Inferência Causal - Rafael Stern
Feature Selection
- Feature Selection - Machine Learning Interview Q&A for Data Scientists - Data Science Interviews - Emma Ding
- Feature Selection Usando Scikit-Learn - Mario Filho
- Como Remover Variáveis Irrelevantes de um Modelo de Machine Learning - Mario Filho
- Seleção de variáveis: uma utilização crítica do Boruta - Carlo Lemos
Python
- Cursos de Python da USP no Coursera - Fábio Kon
- Intermediate Python in 6 hours - freeCodeCamp.org
- Python Programming Beginner Tutorials - Corey Schafer
- Python Tutorial: Iterators and Iterables - What Are They and How Do They Work? - Corey Schafer
- Python Tutorial: Itertools Module - Iterator Functions for Efficient Looping - Corey Schafer
- 8 Design Patterns EVERY Developer Should Know
- Software Design in Python - ArjanCodes
- Write better Python code - ArjanCodes
- Part 1: Cohesion and coupling
- Part 2: Dependency inversion
- Part 3: The strategy pattern
- Part 4: The observer pattern
- Part 5: Unit testing and code coverage
- Part 6: Template method and bridge
- Part 7a: Exception handling
- Part 7b: Monadic error handling
- Part 8: Software architecture
- Part 9: SOLID principles
- Part 10: Object creation patterns
- Programação Funcional
- Flask
- Streamlit
- PySpark
Conformal Prediction
- Distribution-Free Uncertainty Quantification
- “MAPIE” Explained Exactly How You Wished Someone Explained to You - Samuele Mazzanti
Análise de Sobrevivência
- Análise de sobrevivência - Nubank ML Meetup - Jessica De Sousa
- Introduction to Survival Analysis - Pablo Ibieta
Calibração de Probabilidade
Aprendizado Semissupervisionado
Inferência de Rejeitados
Problem Solving
Online Learning
- Machine Learning Types - Batch Learning VS Online Learning - Rocketing Data Science
- Online Learning - Andrew Ng
- Awesome Online Machine Learning Repo - Max Halford
- Read the docs of RiverML
Quantum Machine Learning
Análise de Algoritmos
Open Source
- Contribuindo com o scikit-learn
- How to Contribute to Open Source for Data Scientists - Data Umbrella
Discussões sobre gestão em DS
- Data Science Leadership - Luis Moneda
- Gestão de Cientistas de Dados - Uma Abordagem Heurística não Holística - Nubank ML Meetup - Eduardo Hruschka
- Painel sobre Liderança em times de Ciência de Dados - Nubank ML Meetup
As linhas horizontais desse site foram feitos no Silk.